What is it?
This is an evaluation framework that supports optimization of machine learning (ML) deployments for inference performance. Optimizing the performance of machine learning (ML) models typically focuses on intrinsic factors, such as the number of neurons, depth of layers, or adjusting the numerical precision of computations. Techniques like quantization and pruning are widely used to improve efficiency by reducing the computational or memory footprint of a model. However, these methods inherently involve modifying the model’s internal architecture, which can lead to trade-offs in accuracy. For instance, transitioning from higher-precision floating-point representations to lower-precision integer formats often introduces a loss of numerical precision, which may impact the model’s predictive performance.
Why is it necessary?
How does it work?
To test a model’s performance and scalability characteristics, a model is deployed using a standard ML serving server such as Tensorfow Serve [1]. Once a model is deployed, inferences call to REST and gRPC model server endpoints are generated using a load-testing framework such as locust [2] or a custom script. Using this setup, various scaling characteristics of the model and the model serving infrastructure can be simulated.
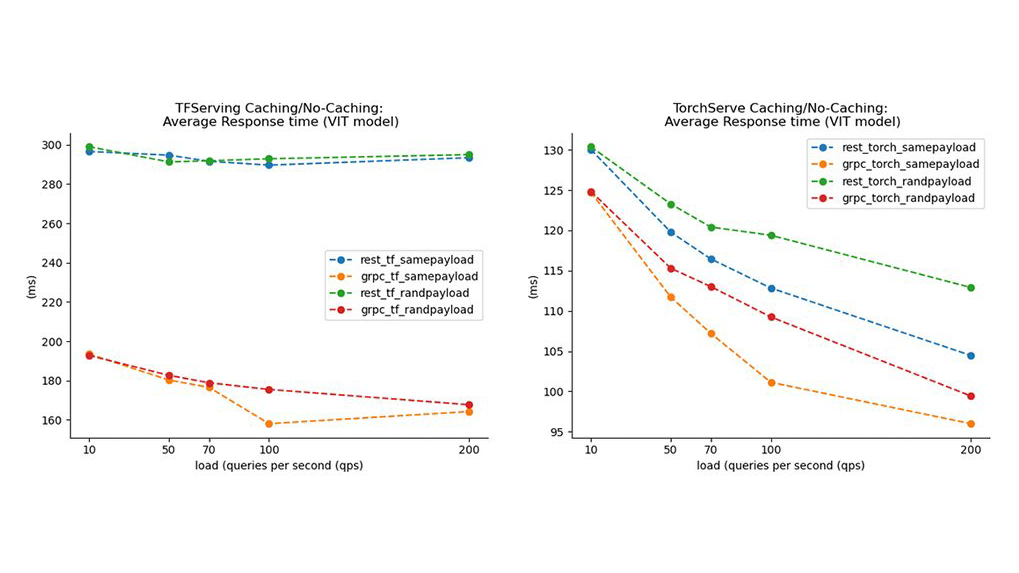
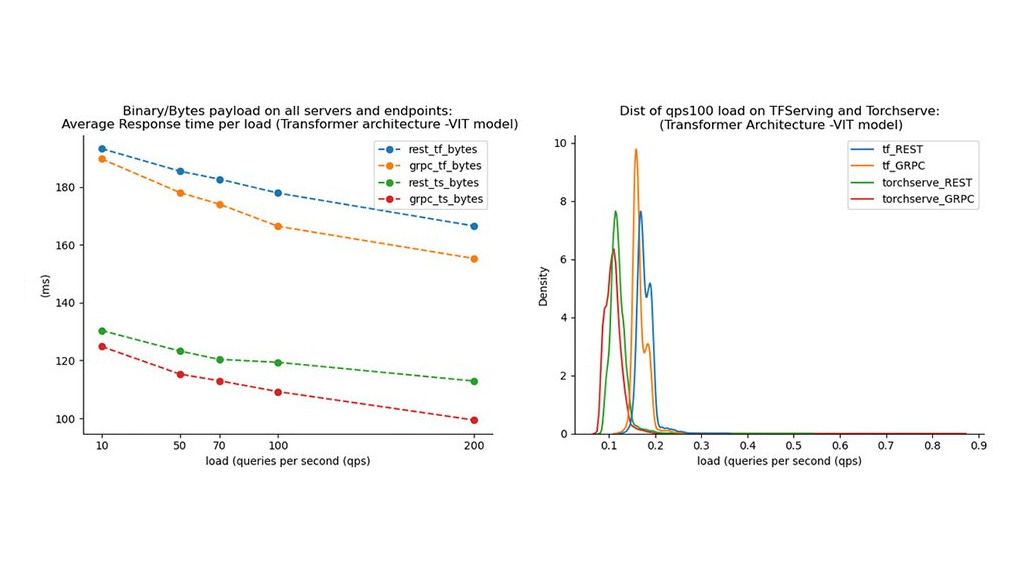
Results
The findings from our experiments indicate that inference protocols, payload characteristics, caching mechanisms, load balancing and integration options should be considered for deployment of ML systems.
- Protocol Selection and Payload Type: Binary payloads are preferred compared to JSON or other text formats. The protobuf serialization is better optimized than JSON which leads to better performance for the gRPC protocol. In settings where REST must be used, binary payloads on REST should be considered. Hybrid inference architectures that use both protocols in strategic parts of the system interface could benefit from the features presented by both protocols. For externally facing APIs, optimized REST APIs should be configured to send more efficient binary payloads to the server.
- Caching: If payloads with similar requests are expected in each deployment setting, a caching layer should be considered. This would improve the overall system performance because of reduced latency to requests and support of caching at the model level. On the downside, an added caching layer may introduce new complexities to the overall architecture.
- Resource utilization: gRPC delivers higher loads to the model server due to its ability to scale at increased request intensity levels.
- Supporting multiple frameworks: Porting the model from one framework to another can be considered for production purposes, by adopting frameworks with demonstrated better performance especially for performance critical applications. The main constraint would be added complexity in the development workflow.
Links and further reading:
- Olston, Christopher, et al. “Tensorflow-serving: Flexible, high-performance ml serving.” arXiv preprint arXiv:1712.06139 (2017).
- Locust. 2023. Locust: An open source load testing tool. (Last visited: 08/05/2023).
- Reddi, Vijay Janapa, et al. “Mlperf inference benchmark.” 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2020.